
Learning to love the red squigglies
One of the things I’m most proud of at LloydsDirect is how we’ve managed to build and maintain a reasonably large number of systems and applications with a relatively small team. There are a number of reasons why I think we’ve been able to do this but this post is about one very practical and technical element that I think has been a big contributing factor - working with strongly-typed compiled languages and typed APIs.
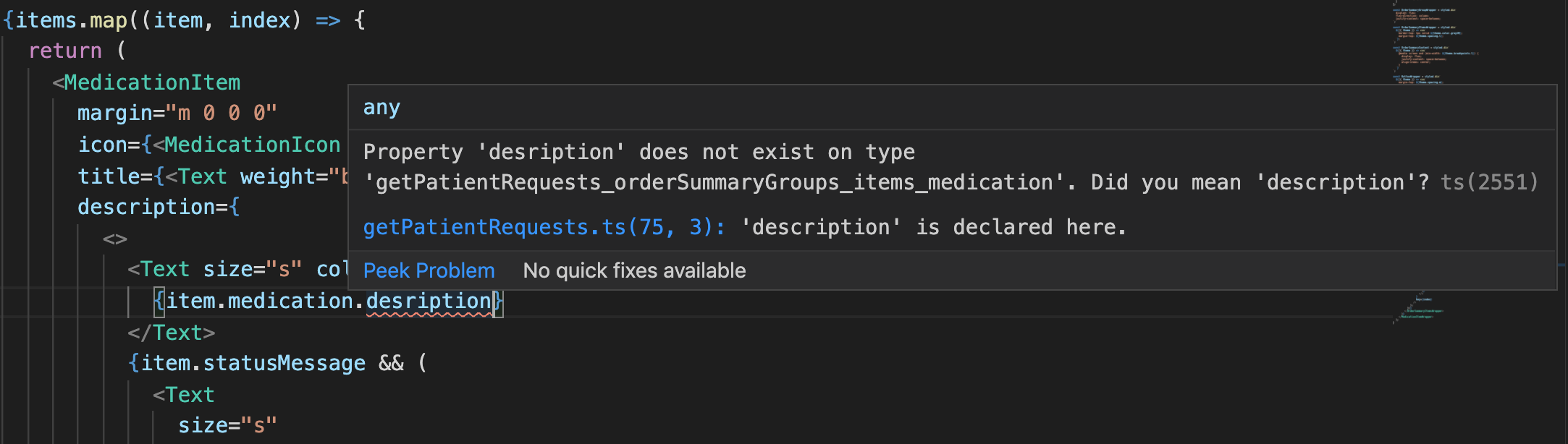
We have way more codebases than engineers and as a result engineers regularly need to jump into a codebase they are not intimately familiar with. When making changes in a codebase you don’t know well there are few things that can help you out though, for example good tests or documentation, but neither of these things can ever cover everything and nor should they have to. Engineers at Echo know they can run commands like go vet or tsc in a project to easily find out if a change they’ve made has caused any compile-time errors. This doesn’t tell you that the change you’ve made is “correct”, as you may have some awful logical error, but it does rule out a whole class of problems from a simple typo to passing completely the wrong arguments to a function.
While running commands in a terminal window is some people’s idea of a good time, most of our team find out about these errors without leaving their editor. Even a large re-factor of some particularly complex code can be done with confidence once all the “red squigglies” have gone away and the tests pass.
The rest of this post will show what this looks like at LloydsDirect by using a simple but real world example of making a UI component that dispays an order status, starting with the UI code and following it back all the way to the database. It’s types all the way down.
The frontend
Our customer-facing web and native apps are written in TypeScript using React and React Native and consume data from a GraphQL API, whilst our internal tools use gRPC-web. In this example we’ll be looking at the former. Since I need to fetch data from the API for my UI component the first thing we’ll do is write the GraphQL query, which goes in it’s own file e.g. graphql/GetOrder.gql.
query GetOrder($id: ID!) {
order(id: $id) {
id
status
}
}Using this query we’re going to now generate two things — the type-definitions for the variables and the response of the query, and some code to actually execute the query. This is done by running a single command (npm run graphql) which does the following:
- Generates a module for each query/mutation that wraps Apollo’s generic
useQueryanduseMutationhooks. This is a custom script. - Downloads the latest GraphQL schema from the production endpoint using
apollo service:download - Generates type definitions for
1by using the schema downloaded in2. This usesapollo client:codegen
The process of generating the type-definitions also checks that the query is valid agaist the schema, and if it isn’t the command will fail explaining why. For example if I keyboard-mash the word status then the command will fail with a helpful error message.
.../app/graphql/hooks/useGetOrderQuery.ts: Cannot query field "statuss" on type "Order". Did you mean "status"?A special 🙌 to tools with error messages that guide you towards a possible solution e.g. “did you mean...”. Once that command has run successfully we can move on to writing the UI component which will use some of the code we just generated.
import * as React from 'react';
// This module was generated from the `npm run graphql` command
import { useGetOrderQuery } from '../../graphql/hooks/useGetOrderQuery';
interface Props {
id: string;
}
export const Order = (props: Props) => {
// note we don’t have to pass the query in here...
const { data } = useGetOrderQuery({
variables: {
// ...and the variables are typed correctly
id: props.id,
},
});
switch (data.order.status) {
case 'STATUS_NEW':
return <p>"Your order has been created"</p>;
case 'STATUS_DISPATCHED':
return <p>"Your order has been dispatched"</p>;
case 'STATUS_CANCELLED':
return <p>"Your order has been cancelled"</p>;
default:
return null;
}
};Here we are using the React hook that was generated by the npm run graphql command. useGetOrderQuery is just a small wrapper around the Apollo library’s generic useQuery hook. We do this to make usage less error-prone as otherwise we’d have to provide the request/response types along with the actual query to useQuery, and it would be reasonably easy to get one of these wrong. By generating this code every query and mutation has its own hook function which has typed variables and response type.
It’s worth nothing that there is almost no “bloat“ introduced by generating this code as it’s nearly all just types which are stripped from the production build.
Finally, I want to call out the use of enums, something we use a lot at LloydsDirect especially for a field like status which have a finite number of possible values. In the example we’ve been looking at so far the status field we are querying is an enum, and that means the values being switched on in the component can also be checked by TypeScript. If I was to make a mistake in one of those case statement then the TypeScript compiler can let me know.
Type '"STATUS_CANELLED"' is not comparable to type 'OrderStatus'.
24 case "STATUS_CANELLED":
~~~~~~~~~~~~~~~~~If we’d typed status as a plain String in GraphQL then we wouldn’t be able to do checks like this. We’ve found it’s really worth taking the time to think about which fields can be defined as enums or which fields can or can’t be null when designing APIs.
In summary for the frontend we:
- Wrote a GraphQL query
- Ran a command to validate our query and generate some code
- Wrote a normal React component that used some of the code we generated
This example is obviously quite simple, but there are pages in our app that make multiple complex queries and then pass that data around as props between many different components, and in those cases having everything typed makes a huge difference to productivity.
The API
Our GraphQL API is written in Go and uses the graph-gophers/graphql-go library. As our internal services are not accessible on the internet our GraphQL API acts as a gateway service, managing authentication and access-control and then handing off to the underyling services where data is persisted and most of our business logic lives. We write our GraphQL schema using the definition language so we have a file that looks something like this.
type Query {
order(id: ID!): Order
}
type Order {
id: ID!
status: OrderStatus!
}
enum OrderStatus {
STATUS_NEW
STATUS_DISPATCHED
STATUS_CANCELLED
}Then for each top-level field that needs resolving (in this example there is only one - order) we write a resolver function.
import (
// importing another service allows us to access its gRPC client
"github.com/echo-health/orders"
)
func (a *Api) Order(ctx context.Context, args struct{ ID string }) (*Order, error) {
// Authentication check happens here...
// Making a gRPC call using the generated orders client
res, err := orders.GetOrdersClient().Get(ctx, &orders.GetRequest{
Id: args.ID,
})
if err != nil {
return nil, err
}
return &Order{
order: res.Order,
}, nil
}This is where we make the call to the relevant underlying service, in this case our Orders service. We make that call using a generated gRPC client that is accessible by importing that service. Although this is a Go service talking to another Go service we also use gRPC for our internal webapps and in those cases we import the clients from a private NPM package e.g. @echo-health/orders.
Originally our GraphQL API used Node.js and was written in JavaScript but we got burnt a number of times by some simple (and avoidable) mistakes so in the end we made the call to re-write it in Go. With our Javascript version we had to be careful to write a test for every single query/mutation to make sure the response from the field resolvers matched the schema (which was checked at runtime). If we didn’t do this there was a chance we’d ship a change to production where a field that should be a Integer was being resolved as a string. This is an example of the kind of thing I just don’t think you just have to write a test to find out, your tooling should help you here.
With the graph-gophers/graphql-go library the resolver is validated when it is initialised at boot time. The library uses reflection to check that the arguments and return types of every field match the schema, and if they don’t it will panic (causing the app the fail to boot). As an example if in the above code I had mistakenly thought that the order field took an orderId input rather than id then the app would fail to boot with this message.
panic: struct { OrderID graphql.ID } does not define field "id"
used by (*resolvers.Api).OrderThis tells me that the struct I’m using to “receive” my variables on the order resolver does not define a field that the schema says exists, in this case id. The same kind of message would be displayed if the return type of a field resolver didn’t match the schema. As I mentioned before, we try to keep our GraphQL API as simple as possible, so there isn’t much more to see here. Let’s move on to the orders service.
The backend
Our backend services are all written in Go and expose a gRPC API. With Protocol Buffers you define your message schema and RPC services in a .proto file like the one below.
message Order {
string id = 1;
OrderStatus status = 2;
}
enum OrderStatus {
STATUS_UNKNOWN = 0;
STATUS_NEW = 1;
STATUS_DISPATCHED = 2;
STATUS_CANCELLED = 3;
}
message GetRequest {
string id = 1;
}
message GetResponse {
Order order = 1;
}
service Orders {
rpc Get(GetRequest) returns (GetResponse);
}Something we’ve found to be really useful for API design disussions and pull requests is having APIs described in a language-agnostic way, without the noise of the implementation. A proto file or a GraphQL schema is much easy to read and reason about than reading the code which implements it.
After making a change to a .proto file we run the protoc tool to generate code to work with the service in both Go and TypeScript. We also use the lile-server plugin to generate some scaffolding for each RPC handler. All that needs to be done then is to actually implement any new RPCs that have been added, and most of our RPCs follow this broad pattern.
- Validate the request
- Read/write some data
- Return a valid response message
In reality this looks something like this.
func (s OrdersServer) Get(ctx context.Context, r *orders.GetRequest) (*orders.GetResponse, error) {
// validate the request
if r.Id == "" {
return nil, status.Error(codes.InvalidArgument, "id must not be empty")
}
// fetch from the database
order, err := db.GetOrder(ctx, r.Id)
if err != nil {
return nil, err
}
// convert from database model to proto model
pbOrder, err := typeconv.DBOrderToPBOrder(order)
if err != nil {
return nil, err
}
return &orders.GetResponse{Order: pbOrder}, nil
}Barring a few exceptions, we write unit tests for every RPC, but as everything here is strictly typed (e.g. no interface{}) we don’t write tests that check the response type of the RPC is correct; if that was the case the code wouldn’t even compile. We’re pretty much at the end of this journey with just one more stop left, the database.
The database
Most of our services store data in a Postgres database and we manage the migrations for these databases with plain SQL files. For example to add a new table we would write a migration something like this.
CREATE TABLE IF NOT EXISTS orders (
id TEXT PRIMARY KEY,
status TEXT NOT NULL,
created_at TIMESTAMP DEFAULT now()
);Some people may prefer working with schemaless databases as they feel it gives them flexibility over the structure of the data they store. Personally I don’t want flexibility here, I want to know that a field is definitely a string and will never be null. If I can be absolutely sure of these things then I don’t have to give it any thought. There are enough things that we do have to think about when building software without having to write overly defensive code handling every edge case under the sun.
As discussed in a previous post we keep our database models and protobuf messages deliberately separate so that we can change the internal implementation of how data is stored without changing the external interface. An example of this is the status field of an order where in GraphQL it’s an enum, in proto it’s an enum, but in the database it’s a text column. It could equally be an integer column as in protobuf an enum is really just an int. The point here is that it doesn’t matter, if we want to change to store that field as an integer we can do that easily.
The following table shows how we generally map types at each level of our system. We also try to be very explicit about things that can and can’t be null, as an example for database columns that can be null we will use a pointer (e.g. *string) in Go to work with that field as otherwise you wouldn’t be able to distinguish between null and an empty string.
| Postgres | Go | Protocol Buffers | GraphQL | TypeScript |
|---|---|---|---|---|
TEXT |
string |
string |
String |
string |
INTEGER |
int32 |
int32 |
Int |
number |
NUMERIC |
float32 |
float32 |
Float |
number |
BOOLEAN |
bool |
bool |
Boolean |
boolean |
TIMESTAMP |
time.Time |
google.protobuf.Timestamp |
custom Date type |
custom Date type |
TEXT |
string |
enum |
enum |
enum |
The end
That’s the end of the journey. From UI to DB we’ve seen how types can remove a lot ambiguity from our code and allow engineers to be more confident when making changes in codebases they are not familiar with.
Follow us on @BuildingLloydsD